Method Overview
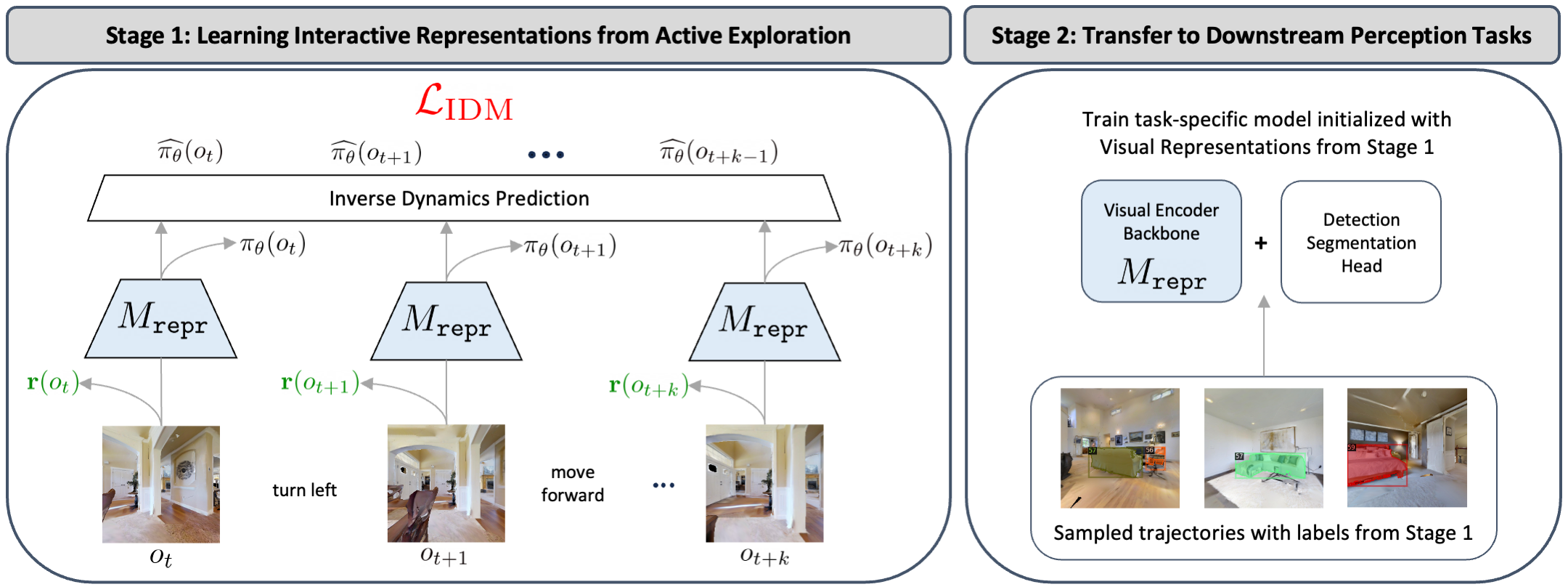
We present ALP, an embodied learning framework based on active exploration for visual representation learning and downstream perception tasks. Our framework consists of two stages.
In Stage 1, we allow the agent to actively explore in visual environments from intrinsic motivation to discover diverse observations. We propose a coupled approach to incorporate action information and learn a set of shared visual representations that jointly optimizes a reinforcement learning objective as indirect action signals and an inverse dynamics prediction loss as explicit action signals.
In Stage 2, we label a small subset of collected samples from active exploration to obtain better training data for downstream perception tasks. We initialize from the pretrained representation in Stage 1 to improve the performance of the perception model.